What is Hibernate ORM?
Hibernate ORM is a popular tool used in Java development for Object-Relational Mapping (ORM). In simpler terms, it acts as a bridge between the object-oriented world of your Java code and the relational database that stores your data. When you design your application using Java classes to represent entities (such as users, products, orders, etc.), Hibernate helps map these classes to corresponding database tables. For example, if you have a User class in Java, Hibernate can automatically create or update the corresponding users’ table in the database.
Key Features
Object Relational Mapping (ORM): Consider your application modeling real-world entities like customers, orders, or products. Traditionally, you’d interact with a database using SQL statements specific to the database structure (tables, columns). Hibernate bridges this gap. You define classes representing your entities with their properties mirroring database columns. Hibernate translates object operations (creating, updating, deleting) into corresponding SQL statements for the underlying database. This allows you to concentrate on your application logic without getting entangled in the complex details of SQL.
JPA Provider: Think of JPA (Java Persistence API) as a standard for data persistence in Java applications. It defines a set of interfaces and annotations for object-relational mapping. Hibernate is a full-fledged implementation of JPA. This means any application written using JPA can leverage Hibernate’s functionalities. Suppose you write your code using JPA annotations, you can switch between different JPA providers (like EclipseLink) without significant code changes.
Idiomatic Persistence: Hibernate allows you to define your persistent classes using standard object-oriented principles. You can leverage inheritance for creating class hierarchies, polymorphism for handling different entity types, and associations and collections to model relationships between entities. This makes your code cleaner, easier to understand, and more maintainable compared to directly manipulating database tables.
High Performance: Performance is crucial for any application. Hibernate employs several techniques to optimize data access:
- Caching: Frequently accessed data is stored in caches, reducing the need for constant database hits.
- Efficient Fetching: Hibernate uses strategies to fetch related entities only when needed, improving performance over naive SQL queries that might join unnecessary tables.
Scalability: As your application grows, Hibernate is built to handle the increased load:
- Connection Pooling: A pool of database connections is maintained to avoid the overhead of creating new connections for each interaction.
- Optimistic Locking: This mechanism helps prevent conflicts when multiple users try to update the same data simultaneously.
Automatic Schema Creation: Based on your persistent classes, Hibernate can automatically generate the corresponding database schema (tables and columns) if it doesn’t already exist.
Database Dialects: Hibernate supports various database vendors (e.g., MySQL, PostgreSQL) using specific dialects to translate operations into the appropriate SQL syntax for each database.
HQL (Hibernate Query Language): HQL is an object-oriented query language that allows you to query your data using familiar object names and relationships, instead of writing raw SQL.
Transaction Management: Hibernate provides functionalities (Java Transaction API (JTA) or local transactions) to group database operations into transactions, ensuring data consistency.
Lazy Loading: Lazy loading is a technique where data is loaded from the database only when the application explicitly accesses it. In Hibernate, this is achieved through associations (such as one-to-many or many-to-one relationships) between entities. When an entity has a related collection (e.g., a list of orders for a customer), Hibernate doesn’t load the entire collection upfront. Instead, it fetches the data on-demand when the application accesses the collection.
Lazy loading helps optimize performance by reducing unnecessary database queries. However, developers need to be mindful of potential issues like N+1 query problems (where multiple queries are executed to fetch related data).
Versioning and Optimistic Locking: These features help maintain data integrity by tracking data versions and preventing conflicts during concurrent updates.
Caching: Caching is crucial for improving application performance. Proper cache management is essential to avoid stale data and memory issues. Hibernate provides several caching mechanisms:
- First-level cache (session cache): This cache stores objects within a session. When an entity is retrieved, it’s stored in the session cache. Subsequent requests for the same entity within the same session use the cached object, avoiding additional database queries.
- Second-level cache: This cache is shared across sessions and can be configured to use various providers (e.g., Ehcache, Infinispan, or Hazelcast). It stores frequently accessed data globally, reducing the load on the database.
Persistent Classes: In Hibernate, persistent classes are Java classes that represent database entities. These classes are mapped to database tables. Developers can use annotations (e.g., @Entity, @Table, @Column) or XML configuration files to define the mapping. Hibernate handles the CRUD (Create, Read, Update, Delete) operations transparently, allowing developers to work with Java objects instead of SQL statements.
Benefits
Hibernate ORM offers several advantages for developers working with Java and relational databases:
Improved Productivity: Suppose you’re writing Java code to interact directly with a database. You’d need to write SQL queries, handle connection management, and translate between data types. Hibernate eliminates this boilerplate code. Instead, you define your Java classes with annotations describing how they map to database tables.
Here’s an example:
public class Employee {
@Id
private int id;
private String name;
private String department;
// Getters and setters
}
Hibernate automatically translates working with Employee objects into CRUD (Create, Read, Update, Delete) operations on the underlying database table. This frees you to focus on application logic rather than low-level database access.
Database Independence: Hibernate uses a dialect specific to your chosen database (e.g., MySQL, PostgreSQL). When you interact with your objects, Hibernate translates them into the appropriate SQL dialect for your database. This allows you to switch databases without changing your application logic. As long as the new database supports the same data types and functionalities, Hibernate handles the translation seamlessly.
Reduced Code Complexity: By eliminating manual SQL manipulation, Hibernate reduces the complexity of your codebase. You no longer need to worry about writing error-prone SQL statements or handling different database driver specifics. This leads to cleaner, more maintainable code.
Object-Oriented Persistence: Hibernate maps Java objects to relational database tables. This means you can leverage the power of object-oriented programming when working with data. You can define relationships between your objects (e.g., an Employee can belong to a Department), and Hibernate translates these relationships into appropriate database table structures and foreign keys.
Automatic Transaction Management: Transactions ensure data consistency in your database. Hibernate automatically manages transactions, ensuring operations either succeed entirely or are rolled back if any errors occur. This simplifies your code and reduces the risk of data inconsistencies.
Caching: For frequently accessed data, Hibernate offers a caching mechanism. This means data retrieved from the database can be stored in memory for faster access on subsequent requests. This significantly improves performance for reads, especially for frequently accessed objects.
Automatic Schema Management: Hibernate can automatically generate the database schema (tables with columns) based on your Java classes with annotations. This can be a huge time saver, especially for initial development. However, it’s important to review the generated schema to ensure it aligns with your specific needs.
Powerful Query Language: Hibernate introduces HQL (Hibernate Query Language), which is similar to SQL but operates on object-oriented concepts. HQL allows you to express complex queries using Java classes and their associations. It supports features like inheritance, polymorphism, and eager or lazy loading of related entities. Developers can write expressive queries without worrying about the underlying database schema.
Open Source and Community Support: Hibernate is an open-source project maintained by the Red Hat Community. Its popularity ensures a vibrant community, extensive documentation, and active forums. Developers can find solutions to common issues, share best practices, and contribute to the framework’s improvement.
Integration with Java EE Frameworks: Hibernate seamlessly integrates with other Java EE (Enterprise Edition) frameworks. For instance, Spring Framework provides built-in support for Hibernate. Developers can leverage Spring’s transaction management, dependency injection, and other features alongside Hibernate.
Native SQL Execution: While HQL is powerful, there are cases where native SQL queries are necessary (e.g., vendor-specific features or complex joins). Hibernate allows executing native SQL alongside its ORM capabilities. Developers can seamlessly switch between HQL and native SQL based on their requirements.
Drawbacks
Hibernate ORM is a fantastic tool for simplifying database access in Java applications, but it’s not without its limitations to consider:
Performance Overhead:
- Generated SQL: Hibernate generates SQL statements on the fly based on your object interactions. While convenient, it can be less performant than hand-written JDBC queries. This is because Hibernate might not always generate the most efficient SQL for a specific scenario.
- Object-Relational Impedance Mismatch: There can be inherent differences between how objects are structured and how data is stored in relational databases. Hibernate bridges this gap, but it can add some overhead in translating between the two.
Complex Joins:
- Mapping File Configuration: Defining complex joins between tables often requires additional configuration in Hibernate mapping files (like HBM or XML). This configuration can become intricate and difficult to maintain, especially for intricate relationships between entities.
- Readability: Overly complex mapping files can make your code less readable for other developers. Striking a balance between flexibility and clarity is crucial.
Batch Processing:
- Focus on Object-Level Persistence: Hibernate is designed for object-oriented persistence, meaning it excels at managing individual objects and their relationships. Bulk operations like mass inserts or updates are less efficient with Hibernate.
- JDBC Alternative: For performance-critical bulk operations, resorting to raw JDBC queries might be a better option. JDBC allows for direct control over the database interaction, enabling optimizations for large data sets.
Learning Curve:
- Conceptual Understanding: Hibernate introduces concepts like object-relational mapping, caching strategies, and lazy loading. Grasping these concepts and using them effectively requires time and practice.
- Configuration Nuances: While Hibernate offers a powerful configuration system, it can be overwhelming for beginners. Understanding the intricacies of configuration files and tuning them for optimal performance takes experience.
Lazy Loading Challenges: Hibernate supports lazy loading, a technique where related entities are loaded only when needed. While this optimizes performance by avoiding unnecessary queries, it can be tricky to manage. Inefficient use of lazy loading can lead to the notorious “N+1 select” problem, where additional queries are executed to fetch related data.
Debugging and Troubleshooting: When issues arise, debugging Hibernate-related problems can be challenging. Developers must understand the underlying SQL generated by Hibernate. Analyzing logs, examining SQL statements, and diagnosing issues related to caching or transaction boundaries require expertise.
Overkill for Small Projects:
- Overhead vs. Benefit: The overhead of introducing Hibernate might outweigh the benefits for simple applications with minimal database interaction. The simplicity of JDBC might be sufficient for such scenarios.
- Learning Investment: The learning curve associated with Hibernate might not be justified for a small project with limited persistence needs.
History
Hibernate ORM’s story began in the early 2000s as a response to the limitations of EJB entity beans for Java data persistence. Frustrated developers, led by Gavin King, created Hibernate as a simpler and more powerful alternative.
Hibernate quickly gained popularity in the open-source world. JBoss, a major software company, recognized its potential and hired key developers to fuel further growth. This move also played a significant role in shaping the future of data persistence in Java.
Hibernate’s design philosophy heavily influenced the creation of JPA, a standard specification for Java persistence. As JPA emerged, Hibernate became a leading provider of JPA implementations.
Throughout the past decades, Hibernate ORM has continued to evolve. New features like improved startup, support for modern Java features, and compliance with evolving JPA standards have been introduced. The latest version, released in March 2024, demonstrates its ongoing development.
Use Cases
Hibernate ORM is a popular object-relational mapping (ORM) framework used in Java applications. Here are some of its common use cases:
Enterprise Applications:
- Reduced Development Complexity: Suppose a complex application with numerous entities and relationships. Manually writing and managing SQL for CRUD (Create, Read, Update, Delete) operations on each entity can be overwhelming. Hibernate abstracts this complexity by automatically translating Java objects to database tables and vice versa. Developers can focus on business logic like order processing or customer management, leaving data persistence to Hibernate.
- Improved Maintainability: Changes to the data model often ripple through the entire application. With Hibernate, modifications to Java classes are reflected in the database schema. This centralized approach minimizes the risk of inconsistencies and simplifies maintenance.
Web Applications:
- Faster Development with JPA: Many web frameworks like Spring leverage JPA (Java Persistence API), which Hibernate implements. JPA provides annotations for defining entities and relationships, enabling concise code for data access. This translates to faster development cycles and easier web application creation.
- Reduced Code Duplication: Hibernate eliminates writing repetitive SQL queries across different parts of your web application. It provides a single, object-oriented interface to access and manipulate data, reducing code duplication and improving code clarity.
Data-Driven Applications:
- Simplified Data Management: In applications like CMS, CRM, or e-commerce, data is king. Hibernate streamlines data management by providing a high-level API for working with objects. Developers can easily retrieve, modify, and save complex data structures without writing complex SQL queries.
- Object-Oriented Data Relationships: Many real-world data models involve relationships between entities (e.g., orders and products in an e-commerce platform). Hibernate excels at mapping these object-oriented relationships to corresponding database tables and foreign keys. This simplifies data retrieval and manipulation for scenarios involving linked entities.
Automatic Table Generation: Hibernate can automatically create database tables based on your Java entities. When you start your application, Hibernate checks the entity definitions and generates the corresponding database schema. This feature simplifies database setup and schema management.
Database Independence: One of Hibernate’s key benefits is its ability to provide database independence. What does this mean? You can write your application code without worrying about the specific database system (e.g., MySQL, PostgreSQL, Oracle) you’re using. Hibernate handles translating your Java code to the appropriate SQL dialect for the chosen database. If you decide to switch databases later, you won’t need to rewrite your application logic.
What are the Key Differences Between Hibernate and JDBC?
Aspect | JDBC | Hibernate |
Definition | API for direct database access using SQL queries. | ORM framework that maps Java objects to database tables. |
Purpose | Low-level database interaction. | Simplified database operations with object-oriented mapping. |
Mapping | Direct mapping to relational model (tables). | Automatic mapping of Java entities to database tables. |
Database Independence | Database-independent (specific code for each database). | Database-independent (same code works with different databases). |
Exception Handling | Checked exceptions (e.g., SQLException). | Unchecked exceptions are managed internally by Hibernate. |
Performance | Lower performance due to manual SQL queries. | Higher performance with features like caching and optimized queries. |
Transaction Management | Manual management of connections and transactions. | Hibernate manages transactions, abstracting details from developers. |
Associations | Manual handling of associates (e.g., foreign keys). | Easier association creation using Hibernate annotations. |
Lazy Loading | Not supported by default; developers handle it explicitly. | Supports lazy loading, loading related data only when needed. |
The choice between JDBC and Hibernate depends on your project’s needs. JDBC might be better if you need full control and performance is critical. Hibernate’s developer-friendliness and features make it the preferred option for most Java applications.
How does Caching Work in Hibernate?
Hibernate caching acts as a middle layer between your application and the database, storing frequently accessed data in memory to boost performance. This reduces database round-trips, leading to faster response times. Here’s a detailed breakdown of the two levels of caching:
First-Level Cache (Session-Level Cache):
- Always On: This cache is mandatory and automatically enabled in every Hibernate session.
- Scope: Limited to a single session. Data retrieved within a session is stored in the cache and reused for subsequent requests within the same session.
- Benefits:
- Fastest retrieval: Since data resides in memory, access is incredibly fast compared to database calls.
- Reduced database load: Less pressure on the database as frequently accessed data is served from the cache.
- Drawbacks:
- Data isolation: Changes made to cached entities within a session might not reflect immediately in other sessions or the database until the session is flushed or closed.
- Memory consumption: Large objects or extensive data can strain memory resources.
- Management:
- Eviction: The evict() method on the session allows the removal of specific objects from the cache.
- Clearing: The clear() method on the session clears the entire first-level cache.
Second-Level Cache (Optional):
- Configuration Required: Unlike the first-level cache, this cache needs explicit configuration to be used. It leverages a caching provider like Ehcache or Hazelcast.
- Scope: Broader than sessions. Data can be shared across multiple sessions and transactions, depending on the configuration. This becomes especially useful for read-heavy applications where different sessions access the same data frequently.
- Benefits:
- Improved scalability: Sharing cached data across sessions reduces database load and improves application scalability.
- Consistency options: Configurability allows for defining how cache updates are reflected in the database (write-through, write-behind).
- Drawbacks:
- Increased complexity: Setting up and managing a second-level cache adds complexity compared to the simpler first-level cache.
- Potential for stale data: Invalidation strategies need to be implemented to ensure cached data remains consistent with the database.
Choosing the Right Cache:
The choice between first-level and second-level cache depends on your application’s needs. Here’s a general guideline:
- First-level cache: Ideal for frequently accessed data within a single session, especially for read-heavy scenarios with short-lived sessions.
- Second-level cache: Choose this for data shared across sessions, or for applications requiring fine-grained control over caching behavior and consistency.
Additional Considerations:
- Cache Expiration: Implement strategies to ensure cached data doesn’t become stale, especially for frequently updated entities. This can involve time-based expiration or invalidation mechanisms triggered by database updates.
- Cache Monitoring: Monitor cache hit rates and sizes to assess caching effectiveness and identify potential memory bottlenecks.
Architecture
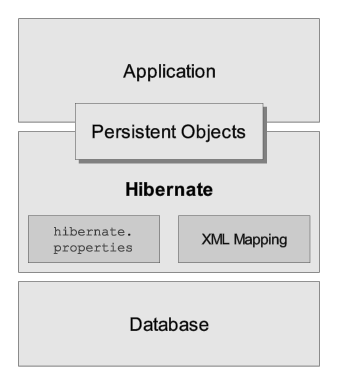
Hibernate uses a layered architecture to provide an abstraction between the Java world and the relational database world. This layered approach simplifies development and reduces the need for developers to write complex SQL code.
Configuration Layer:
- Configuration File (hibernate.cfg.xml): This file defines essential settings for Hibernate, including:
- Database Connection Details: Specifies the database type, driver, URL, username, and password for connecting to your database.
- Dialect: Defines the specific SQL dialect of your database (e.g., MySQL, Oracle) to ensure Hibernate generates appropriate SQL queries.
- Connection Pooling: Configures connection pooling to manage database connections efficiently and avoid creating new connections every time you interact with the database.
- Mapping File Locations: Specifies the location of mapping files that define object-relational mappings.
- Mapping Files (yourclass.hbm.xml): These files map your Java classes to database tables. They define:
- Class-to-Table Mapping: Defines how a Java class corresponds to a database table.
- Property-to-Column Mapping: Specifies how individual properties of a Java class map to specific columns in the table.
- Relationships: Defines how objects relate to each other in the database (e.g., one-to-one, one-to-many, many-to-many). You can use annotations within your Java classes to achieve this instead of separate mapping files.
Service Layer:
- SessionFactory:
- A heavyweight object that creates and manages Session instances. It’s expensive to create, so it’s typically a singleton object in your application.
- It maintains a pool of connections to the database based on your configuration.
- It reads mapping files (or annotations) to understand the object-relational relationships.
- Session:
- Represents a single unit of work (e.g., a single user interaction). It’s short-lived and not thread-safe. You typically create a new session for each database operation.
- Provides methods to:
- Retrieve objects from the database (using queries or object identification).
- Persist (save) new objects.
- Update existing objects.
- Delete objects.
- Manage transactions (begin, commit, rollback).
- Maintains a first-level cache that stores recently accessed objects to improve performance by avoiding redundant database queries.
Object/Relational Mapper (ORM) Layer:
- This layer is the core of Hibernate. It translates between Java objects and database tables.
- Object-Relational Mapping: Defines how Java classes map to database tables and vice versa. This mapping can be done in two ways:
- Annotations: You can directly embed mapping information within your Java classes using annotations like @Entity, @Id, @Column, etc.
- Mapping Files (XML): These files define the mapping details as explained earlier.
- Persistence API: Hibernate uses the Java Persistence API (JPA) to perform object-relational mapping. This allows for a standardized way to interact with different persistence providers.
- Query Language: Hibernate provides its own query language (HQL – Hibernate Query Language) that resembles SQL but works with Java objects instead of tables and columns. You can also use native SQL queries within Hibernate.
JDBC/JTA Layer:
- JDBC (Java Database Connectivity): This layer provides a basic API for interacting with relational databases. Hibernate uses JDBC under the hood to connect to the database, execute SQL statements, and retrieve results.
- JTA (Java Transaction API): This layer allows Hibernate to manage transactions within the context of a larger application server transaction. It ensures data consistency by guaranteeing all database operations within a transaction succeed or fail together.
Benefits of Layered Architecture:
- Simplified Development: You work with Java objects and HQL instead of complex SQL, making development easier and faster.
- Database Independence: Your code is less coupled to the specific database schema. Changing database vendors becomes easier as Hibernate handles the underlying SQL generation.
- Object-Oriented Design: Hibernate aligns with object-oriented programming principles by allowing you to persist your objects directly.
- Improved Performance: Caching mechanisms, connection pooling, and efficient query generation contribute to better performance.
Why Should You Use Hibernate ORM?
You might choose to use Hibernate ORM for your project for several reasons.
Hibernate ORM is a Java-based framework that is particularly useful in addressing the mismatch between object-oriented classes of an application and a relational database. This is achieved using an XML mapping file which serves as a bridge connecting these two different paradigms.
One of the key features of Hibernate is its transparent persistence. This means that the framework automatically manages the connection between the application’s objects and the database tables. This eliminates the need for developers to write extensive code to establish these connections, thereby simplifying the development process.
Another significant advantage of Hibernate is its database independence. It can be used with various databases, including Oracle, MySQL, Sybase, and DB2. This flexibility allows developers to switch between different databases with minimal changes to the code.
Hibernate also introduces a powerful query language known as Hibernate Query Language (HQL). Unlike SQL, which is structured and rigid, HQL is completely object-oriented. This makes it more flexible and powerful, allowing developers to write complex queries easily.
Caching is another important feature provided by Hibernate. It supports both first-level and second-level caching mechanisms. The caching concept allows Hibernate to store objects in the cache, reducing the number of repeated hits to the database. This can significantly improve the performance of the application.
Lastly, Hibernate supports optimistic locking through its version property feature. This allows multiple transactions to occur simultaneously without affecting each other. This is particularly useful in multi-user environments where concurrent transactions are common.
In summary, Hibernate ORM provides a range of features that simplify the development process and improve the application performance. By leveraging these features, developers can focus more on the business logic of the application and less on low-level database interactions. This makes Hibernate a popular choice for many Java-based applications.
How do I set up Hibernate in My Project?
Setting up Hibernate in your project involves several steps:
Step 1: Create a Java Project You start by creating a new Java project in your preferred Integrated Development Environment (IDE). This could be Eclipse, IntelliJ IDEA, NetBeans, or any other IDE that you’re comfortable with.
Step 2: Add Hibernate Jar Files Next, you need to add the Hibernate libraries to your project. These libraries, also known as JAR files, contain the classes and interfaces that Hibernate uses to interact with your database. You can download these JAR files from the official Hibernate website and add them to your project’s build path.
Step 3: Create a Persistent Class A persistent class in Hibernate is a Java class that represents a table in your database. Each instance of this class corresponds to a row in the table. The properties of the class correspond to the columns of the table. You need to create a persistent class for each table that you want to interact with in your database.
Step 4: Create a Mapping File The mapping file is an XML file that tells Hibernate how to map the properties of your persistent class to the columns of your database table. This file needs to be created for each persistent class. It includes the class name, table name, and a mapping for each property in the class to a column in the table.
Step 5: Create a Configuration File The configuration file is another XML file that contains information about your database and the mapping files. This includes the URL of your database, the username and password to connect to the database, the database dialect (which tells Hibernate what type of database you are using), and the names of your mapping files.
Step 6: Create a Class to Store/Retrieve Persistent Objects This is a Java class that you will use to store and retrieve instances of your persistent class. This class will contain the main method where you will create, read, update, or delete records in the database.
Step 7: Run the Application Finally, after setting up all the necessary files and classes, you can run your application. If everything is set up correctly, Hibernate will take care of the rest, managing the connection to your database and the persistence of your objects.
Here’s a more detailed example of a Hibernate configuration file:
<!DOCTYPE hibernate-configuration PUBLIC
“-//Hibernate/Hibernate Configuration DTD 3.0//EN”
“http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd”>
<hibernate-configuration>
<session-factory>
<!– Database connection settings –>
<property name=”hibernate.connection.driver_class”>com.mysql.jdbc.Driver</property>
<property name=”hibernate.connection.url”>jdbc:mysql://localhost:3306/DBNAME</property>
<property name=”hibernate.connection.username”>USERNAME</property>
<property name=”hibernate.connection.password”>PASSWORD</property>
<!– SQL dialect –>
<property name=”hibernate.dialect”>org.hibernate.dialect.MySQLDialect</property>
<!– Mapping files –>
<mapping resource=”com/example/YourClass.hbm.xml”/>
</session-factory>
</hibernate-configuration>
In this file, replace DBNAME, USERNAME, PASSWORD, and YourClass with your actual database name, username, password, and your class name respectively.
Remember to add the Hibernate jar files to your project’s build path. If you’re using Maven or Gradle, you can add the Hibernate dependency to your pom.xml or build.gradle file.
Competitors
EclipseLink
EclipseLink and Hibernate are both well-known implementations of the Java Persistence API (JPA), a specification that manages relational data in Java applications. EclipseLink is the reference implementation for JPA 2, which means it closely follows the JPA standards. This adherence to standards can be beneficial in certain situations. Additionally, EclipseLink allows you to call native SQL functions directly in your Java Persistence Query Language (JPQL) queries, which can provide more flexibility in how you interact with your database. In terms of efficiency, EclipseLink is slightly more efficient than Hibernate when retrieving JPA entity objects from a MySQL server.
On the other hand, Hibernate is a more mature framework with a larger community, which can be beneficial when seeking help or resources. The documentation for Hibernate is generally considered to be more comprehensive, and its error messages are often more informative, which can make debugging easier. However, Hibernate does have some compliance issues with JPA 2, which might be a concern depending on your project’s requirements. Unlike EclipseLink, Hibernate does not allow you to call native SQL functions directly in your JPQL queries.
In conclusion, both EclipseLink and Hibernate have their own strengths and weaknesses, and the choice between the two often depends on the specific needs of your project. If strict standards compliance or the ability to call native SQL functions directly in your JPQL queries is important to you, then EclipseLink might be the better choice. Conversely, if you value a mature framework with a large community and comprehensive documentation, then Hibernate might be more suitable.

MyBatis
MyBatis is an open-source, lightweight persistence framework. It is known for its simplicity and ease of understanding, especially for new developers. MyBatis uses SQL language, which is familiar to most developers and provides a clear and direct way to interact with the database. This framework supports Independent Interfaces, Stored Procedures, and Dynamic SQL, which can be particularly useful when working with complex projects that are SQL-specific. Since MyBatis is not an Object Relational Model (ORM), it does not suffer from ORM impedance mismatch, a common issue where there is a conceptual mismatch between the object and relational models. MyBatis is more database-centric, meaning it focuses more on the database and SQL aspects of data persistence.
On the other hand, Hibernate is an open-source, Object Relational Model (ORM), and a more complex tool compared to MyBatis. It maps the application domain objects with the database tables and vice versa, providing a seamless way to manage data persistence. Hibernate uses the Hibernate Query Language (HQL) which is not specific to any databases, so scalability and migration are quite easy. It provides powerful functions, excellent mapping, data independence, and portability which helps in faster and smoother development. Unlike MyBatis, Hibernate is more object-centric, focusing more on the object model and less on the underlying SQL and database structure.
In terms of scalability, MyBatis is considered to have limitations as all SQL is written in the database. This could potentially make it more difficult to scale or migrate to a different database system. In contrast, Hibernate writes all the database-specific specifications in XML, so HQL does not need to worry about which database is used and its migration. This makes Hibernate more scalable and flexible in terms of database migration.
In summary, if your view is more object-centric and you want a framework that handles a lot of the database interactions for you, Hibernate might be a better choice. If your view is more database-centric and you want more control over the SQL that is used, MyBatis might be a better choice.

QueryDSL
Hibernate is a well-known Object-Relational Mapping (ORM) framework that offers a comprehensive set of features for mapping Java objects to database tables. This allows developers to work with persistent objects, which simplifies the querying and manipulation of database data. Hibernate uses Hibernate Query Language (HQL), a SQL-like language that enables developers to write queries using object-oriented concepts. However, a potential drawback of HQL queries is that they are not type-safe, which can lead to runtime errors if the query does not match the object model.
In contrast, QueryDSL is a query library that provides a fluent API for constructing type-safe SQL-like queries. It can be integrated with various ORM frameworks, including Hibernate, JPA, and others. One of the key advantages of QueryDSL is its emphasis on type safety. It leverages the Java compiler to detect errors at compile time, which can significantly reduce the occurrence of runtime errors.
When it comes to the learning curve and complexity, Hibernate, being a powerful ORM framework, has a steep learning curve. Developers need to understand complex concepts such as session management, entity states, and caching strategies. On the other hand, QueryDSL, being a simple query library, is easier to use and has a lower learning curve.
In conclusion, your choice between Hibernate and QueryDSL would depend on your specific needs. If you require a feature-rich ORM framework that supports advanced database operations and caching, Hibernate might be the better choice. However, if you prefer a lightweight query library that focuses on simple and type-safe query construction, QueryDSL could be more suitable.

JOOQ (Java Object Oriented Querying)
Hibernate is an Object-Relational Mapping (ORM) framework. It provides a high-level abstraction over the database, allowing developers to interact with the database using Java objects and their relationships. This means that you can work with objects in your code, and Hibernate takes care of translating those operations into database queries. It also handles complex CRUD operations and supports various caching mechanisms. Hibernate uses Hibernate Query Language (HQL), which is a SQL-like query language. With HQL, you can write database queries using Java objects and their relationships. This provides an abstraction over the actual SQL, enabling you to work with object-oriented concepts. One of the key advantages of Hibernate is that it abstracts the underlying database, allowing you to write database-independent code.
On the other hand, jOOQ is a Query-Object Relational Mapping (QORM) framework. It focuses on generating type-safe SQL queries and capturing the full power and expressiveness of SQL. Unlike Hibernate, jOOQ takes a more direct approach by generating SQL queries at compile-time based on your specifications. This gives you complete control and flexibility over the query creation process. jOOQ allows you to write SQL queries in a type-safe and convenient manner. This means you can leverage the full features and optimizations provided by the underlying database. jOOQ embraces the specific features and syntax of each supported database, generating SQL code tailored to the target database.
In essence, the choice between jOOQ and Hibernate depends on your specific use-case and requirements. If your application design drives your data model and you just want to “persist” your Java domain somewhere, then Hibernate might be a better choice. On the other hand, if your data model drives your application design and you do mostly complex reading and simple writing, then jOOQ might be a better choice.

ObjectDB
ObjectDB is an object-oriented database management system (ODBMS), which means it’s designed to work with object-oriented programming languages like Java. It’s a type of NoSQL database, which means it doesn’t use the traditional table-based relational database structure. Instead, it uses a model that’s more like how data is represented in applications, which can make it easier to work with. One of the key advantages of ObjectDB is its speed. Because it’s not an Object-Relational Mapper (ORM) like Hibernate, it doesn’t have the overhead of converting between objects and tables, which can make it faster.
On the other hand, Hibernate is an ORM, which means it’s designed to map objects from an object-oriented programming language to a relational database. This can make it easier to work with relational databases, as you can work with objects in your code and let Hibernate handle the conversion to tables. However, this conversion process can introduce some overhead, which can make Hibernate slower than ObjectDB in some cases.
In terms of performance, studies have found that ObjectDB can be more efficient than Hibernate when it comes to persisting and retrieving JPA entity objects to and from the database. However, the performance can vary depending on the specific use case and requirements.

Apache Cayenne
Apache Cayenne and Hibernate are both well-known Object-Relational Mapping (ORM) frameworks used in Java. They each have their own strengths and weaknesses, and the choice between the two often depends on the specific needs of your project.
Apache Cayenne has received a rating of 4.3 out of 5 stars based on 15 reviews. Reviewers have indicated that Apache Cayenne is better suited to their business needs compared to Hibernate. In terms of ongoing product support, Apache Cayenne is the preferred choice among reviewers. Furthermore, when it comes to feature updates and roadmaps, reviewers have shown a preference for the direction of Apache Cayenne over Hibernate.
On the other hand, Hibernate has a slightly lower rating of 4.2 out of 5 stars, based on 28 reviews. Some users have reported that Hibernate is not as user-friendly as Apache Cayenne.

CUBA Platform
Hibernate is a Java framework that simplifies database operations in Java applications. It’s an Object-Relational Mapping (ORM) tool, which means it maps Java classes to database tables and Java data types to SQL data types. This makes it easier for developers to work with databases using Java. Hibernate is a lower-level tool that handles the persistence layer in Java applications, which is the layer responsible for storing and retrieving data from the database.
On the other hand, CUBA Platform, which has been renamed to Jmix, is a high-level open-source Java framework designed for the rapid development of business applications. It provides a comprehensive set of built-in features and development tools, allowing developers to focus on business tasks rather than the underlying technologies. One of the components of the CUBA Platform is JPA Buddy, which is designed to assist with projects that use JPA and related technologies, including Hibernate.
So, while Hibernate is focused on the persistence layer, CUBA Platform provides a more comprehensive solution for building applications. They are not direct competitors because they serve different purposes and can be used together in the same application. In fact, Hibernate can serve as the ORM implementation within a CUBA Platform application. So, they can be seen as complementary tools that can be used together to build robust and efficient applications.

Slick
Slick is a modern database query and access library for Scala. It’s designed with a focus on functional programming, which is a paradigm that treats computation as the evaluation of mathematical functions and avoids changing-state and mutable data. This approach can lead to more predictable and easier-to-test code. Slick provides a type-safe way to write SQL-like queries in Scala, which can help prevent errors that might occur due to incorrect data types. However, one thing to note about Slick is that it doesn’t use any caches, which means it might not perform as well as other libraries for certain use cases. Additionally, while you can predict the semantics and the rough structure of the SQL query that Slick will produce, you can’t predict the exact SQL query. This means that Slick relies on your database’s query optimizer to execute the SQL query efficiently.
On the other hand, Hibernate is an Object-Relational Mapping (ORM) library for Java. It’s been around for a while and is known for its maturity and wide range of features. Hibernate provides a way to map between objects in code and database tables. This allows for object-oriented programming with relational databases, which can make working with databases more intuitive for developers used to object-oriented programming. Unlike Slick, Hibernate does use a cache to improve performance, which can make it faster for certain use cases.
In summary, if you’re working with Scala and prefer a functional programming style, Slick might be a good choice. If you’re working with Java and need a mature, feature-rich ORM, Hibernate could be more suitable.

Apache Torque
Hibernate is a mature and stable framework that has been around for a while. It’s known for implementing the Java Persistence API (JPA), including the latest version, JPA 2.0. This means it adheres to a standard interface, making it easier to use with various application servers and databases. Hibernate also supports annotations, which can simplify the mapping between Java classes and database tables. Moreover, Hibernate is actively maintained, which ensures that it stays up-to-date with the latest technologies and best practices.
On the other hand, Apache Torque has its unique strengths. It’s known for generating a significant amount of code, which can be customized to suit the needs of your application. This can save a lot of time and effort, especially for large projects. Torque is particularly effective when your operations map directly to the database tables. With Torque, you don’t need to write code for beans or Plain Old Java Objects (POJOs) and annotations, as most of them are generated automatically. Most of the SQL code is already in the ORM classes, which can make your code cleaner and easier to maintain. Furthermore, Torque doesn’t require any configurations to handle POJOs, which can simplify the setup process.
However, it’s important to note that Torque hasn’t had any updates since September 2008. While it has its benefits, the lack of active development could be a concern, especially for long-term projects. In contrast, Hibernate’s active development and broader feature set might make it a more attractive choice for many applications.

Speedment
Speedment is a Java Stream ORM toolkit and runtime that is designed to simplify the development of database applications. It does this by allowing developers to use pure Java streams, which eliminates the need to write a separate mapping layer or use SQL or Hibernate. This can be particularly beneficial for projects that want to leverage the power and simplicity of Java Streams for their data access. Additionally, Speedment offers the ability to update an existing software monolith to meet modern demands without the need for risky and costly migrations. This is achieved by decoupling the application layer from the underlying datasource, which can lower the cost of maintenance and enable total agility.
On the other hand, Hibernate is an open-source Java persistence framework project. It provides a robust framework for mapping an object-oriented domain model to a relational database. This can be particularly useful for projects that have a complex domain model with many relationships, as Hibernate’s object-relational mapping capabilities are both robust and mature. Hibernate handles object-relational impedance mismatch problems by replacing direct, persistent database accesses with high-level object-handling functions.
If you prefer working with Java Streams and want to avoid SQL or Hibernate, then Speedment might be a good fit for your project. However, if your project involves a complex domain model with many relationships, then Hibernate’s robust and mature object-relational mapping capabilities might be more suitable.

Ebean ORM
When it comes to SQL execution, Ebean ORM is known for always honoring firstRows / maxRows in the generated SQL. This is not the case with Hibernate, which stops implementing maxRows in SQL once you include a join fetch to a @OneToMany. Instead, Hibernate brings all the rows back to the client (application server) and filters the results there.
Another difference lies in the generation of SQL cartesian products. Ebean ORM never generates a SQL cartesian product. On the other hand, Hibernate does generate a SQL cartesian product when you join fetch multiple @OneToMany or @ManyToMany associations.
In terms of lazy loading, Hibernate does not allow it beyond the end of its Session scope and instead throws LazyInitialisationException. Contrarily, Ebean allows lazy loading beyond the initial scope.
Session management is another area where these two ORMs differ. Ebean is a sessionless ORM, so you don’t need to think about sessions. However, Hibernate has a first-level cache which is impossible to disable.
As a byproduct of Ebean supporting lazy loading (beyond transaction scope), Ebean does not require the “Open session in view” pattern which is sometimes used with Hibernate.
Lastly, when comparing Ebean’s @History with Hibernate Envers, Ebean’s @History is a database-centric approach mapping to SQL2011.

DataNucleus
DataNucleus is a highly standards-compliant Open Source Java persistence product. It adheres to a wide range of Java standards including JDO1, JDO2, JDO2.1, JDO2.2, JDO3, JPA1, and JPA2. It also complies with the OGC Simple Feature Specification for the persistence of geospatial Java types to RDBMS. One of its unique features is its OSGi-based plugin mechanism, which makes it extremely extensible. A notable advantage of DataNucleus over Hibernate is its efficiency. It doesn’t have all the runtime reflection overhead and is more memory efficient because it uses build-time byte code enhancement.
On the other hand, Hibernate is a high-performance Object/Relational persistence and query service. It handles the mapping from Java classes to database tables and from Java data types to SQL data types. It also provides data query and retrieval facilities that can significantly reduce development time.
When it comes to performance, Hibernate generally outperforms DataNucleus. In particular, in the retrieval by ID scenario, Hibernate is almost 9 times faster than DataNucleus. However, there are cases where DataNucleus can be faster, such as when using graphs of objects with small retrieval sizes.

Companies Using Hibernate
Amazon
Amazon uses Hibernate in its Elastic Compute Cloud (EC2) service. Hibernate is a feature that allows an EC2 instance to be paused or “hibernated” and then resumed later, maintaining its state across the hibernation period.
When an EC2 instance is hibernated, Amazon EC2 signals the operating system to perform hibernation, which is essentially a suspend-to-disk operation. This process freezes all of the processes, saves the contents of the RAM to the EBS root volume, and then performs a regular shutdown.
After the shutdown is complete, the instance moves to the stopped state. Any EBS volumes remain attached to the instance, and their data persists, including the saved contents of the RAM1. However, any data on instance store volumes is lost.
While the instance is in the stopped state, certain attributes of the instance can be modified, including the instance type or size. In most cases, the instance is migrated to a new underlying host computer when it’s started.
When the instance is started, the instance boots up and the operating system reads in the contents of the RAM from the EBS root volume, before unfreezing processes to resume its state. The instance retains its private IPv4 addresses and any IPv6 addresses. However, Amazon EC2 releases the public IPv4 address and assigns a new public IPv4 address to the instance when it is started.
The instance also retains its associated Elastic IP addresses, and users are charged for any Elastic IP addresses that are associated with a hibernated instance.
Hibernation is particularly useful for instances or applications that take a long time to bootstrap and build a memory footprint to become fully productive. By using hibernation to pre-warm the instance, users can bring the instance to a desired state, hibernate it, and then have it ready to be resumed to the desired state whenever needed.
IBM
IBM uses Hibernate in a couple of ways, primarily through the transformation of UML models into Hibernate elements and vice versa.
IBM’s Rational Software Architect Designer supports the transformation of UML models into Hibernate elements. This process involves generating Hibernate elements with Hibernate-specific annotations from a UML model that has the Hibernate and JPA profiles applied. This transformation can be used in two round-trip-engineering (RTE) scenarios:
- Transforming a UML model into code, changing the code, and then transforming the changed code back into UML (model-code-model).
- Transforming existing Hibernate annotations and Java code into a UML model, changing the model, and then transforming the changed model back into Java code with Hibernate annotations (code-model-code).
In the second scenario, the existing Hibernate annotations and Java code elements must be linked to the UML model elements in the model that the Hibernate-to-UML transformation generates. This linking adds annotations and comments to the code so that the UML-to-Hibernate transformation can propagate the UML changes to the Hibernate annotations and Java code, and preserve existing method bodies.
IBM also supports the transformation of Hibernate annotations into UML model elements. This involves generating UML models from Hibernate-annotated Java code or a Hibernate mapping file (deployment descriptor).
In addition, IBM uses the db2jcc4.jar driver (jdbc driver) to allow Hibernate to communicate with Db2. This combination is well-known and is often used in development environments.
Overall, IBM’s use of Hibernate is centered around transforming UML models and Hibernate elements, allowing for a seamless integration of the two technologies.
Oracle
Oracle uses Hibernate, an open-source Object-Relational Mapping (ORM) solution, to facilitate data query and retrieval in Java applications. Here’s an in-depth explanation of how Oracle uses Hibernate:
Hibernate allows Oracle to develop persistent classes following an object-oriented idiom. This includes association, inheritance, polymorphism, composition, and collections. These persistent classes are used to represent database tables and the relationships between them.
Hibernate provides a way to express queries in its own portable SQL extension, known as Hibernate Query Language (HQL), as well as in native SQL. It also offers an object-oriented Criteria and Example API for expressing queries.
In a typical setup, Oracle configures spring.jpa.hibernate.ddl-auto for database initialization. The value is set to update so that a table will be created in the database automatically corresponding to the defined data model.
Oracle uses Spring Boot and Hibernate to build CRUD (Create, Read, Update, Delete) applications. For instance, a tutorial application might have APIs to create, retrieve, update, delete, and find tutorials. These operations are performed using Hibernate and Spring Data JPA’s JpaRepository.
The database used in these applications can be Oracle 12c/19c, configured through project dependency and datasource. This allows Oracle to leverage the power of Hibernate with its own database systems.
In summary, Hibernate significantly reduces development time by providing data query and retrieval facilities, allowing Oracle to develop persistent classes following an object-oriented idiom, and offering a way to express queries in a variety of formats.
eBay
eBay, like many other large-scale web applications, utilizes Object-Relational Mapping (ORM) techniques to bridge the gap between their logical business model and their physical storage model. One of the ORM frameworks that eBay uses is Hibernate.
Hibernate is a Java-based ORM framework that maps object-oriented domain models to a traditional relational database. It simplifies the process of working with relational data sources by abstracting the underlying SQL commands needed for data persistence and retrieval.
eBay uses Hibernate in conjunction with the CData JDBC Driver for eBay to generate an ORM of their eBay repository. This allows eBay to map their object-oriented domain models to their relational database, which is a common use case for Hibernate.
The process involves installing the Hibernate plugin in Eclipse, starting a new project, adding the necessary driver JARs, and configuring the connection properties to eBay data. Once this setup is complete, eBay can use Hibernate to manage its data persistence and retrieval processes.
This setup allows eBay to leverage the power of Hibernate’s features, such as transaction management and caching, to optimize their database interactions. It also provides eBay with a robust and scalable solution for managing its vast amounts of data.
LinkedIn uniquely uses Hibernate, not as a Java persistence framework, but as a feature to allow users to take a break from their LinkedIn activities. This feature is known as “Hibernate your LinkedIn account”.
When a user decides to hibernate their LinkedIn account, they are essentially putting their account into a state of inactivity. This is similar to deactivating the account but with some key differences. During the hibernation period, the user’s profile becomes completely invisible to all other LinkedIn users, including their connections.
The user’s profile information will not be accessible on the platform during this period. Any recommendations and endorsements they’ve given to others will still exist, but they will be attributed to an anonymous entity called “A LinkedIn member”. Similarly, their message history will be retained, but their identity will be masked, displaying them only as “A LinkedIn member”.
While the account is in hibernation, the user’s profile will not appear in any searches conducted on LinkedIn. This includes searches made through other LinkedIn products like Recruiter.
The user’s posts and comments will remain intact, but their identity will be replaced by a generic icon if they have a profile photo. This signifies their temporary absence from the platform.
In summary, LinkedIn’s hibernation mode ensures the complete invisibility of the user’s profile, shielding it from direct connections and platform-wide searches. While the user’s past interactions and contributions persist, they are anonymized during this period, with their identity being replaced by a generic label. This maintains their privacy and online absence until they choose to reactivate their account.
SAP
Hibernate is an open-source Object-Relational Mapping (ORM) framework that SAP uses to map an object-oriented domain model written in Java to a relational model that can be persisted in a relational database.
The primary purpose of Hibernate is to present the user with an abstraction of the database, thereby freeing the user from knowing too many details about the representation of the data in the database. The user only deals with the objects of the object-oriented model and can stay entirely within the concepts of the Java programming language.
Hibernate solves the so-called “object-relational impedance mismatch”, i.e., it takes care of the conceptual differences between the object-oriented model and the relational model. The database specifics are implemented as so-called dialects that are called by the Hibernate core to generate valid SQL statements for the different database systems.
The general concept of object-relational mapping has been standardized in Java by the Java Persistence API (JPA). Hibernate is also an implementation of the JPA and can therefore be used with any JPA-compliant application.
SAP HANA, express edition, uses Hibernate ORM to create Java applications. These applications leverage the SAP HANA Spatial capabilities. For example, developers can create an application to process geospatial data using Hibernate. They can also create an app-consuming calculation view using Hibernate on SAP HANA.
In summary, Hibernate ORM provides a powerful and flexible framework for mapping an object-oriented domain model to a relational database. SAP leverages this framework to create robust and efficient Java applications that can interact with their HANA database system.
Google uses Hibernate ORM with its Cloud Spanner database. Hibernate is an object-relational mapping tool for the Java programming language. It provides a framework for mapping an object-oriented domain model to a relational database.
Google integrates GoogleSQL-dialect databases with Hibernate using the open-source Spanner Dialect (SpannerDialect). Spanner is compatible with Hibernate ORM 6.3. Spanner Dialect produces SQL, DML, and DDL statements for the most common entity types and relationships using standard Hibernate and Java Persistence annotations.
To set up Hibernate in a project, Apache Maven dependencies for Hibernate ORM core, Spanner Dialect, and the Spanner officially supported Open Source JDBC driver are added. The hibernate.cfg.xml is configured to use Spanner Dialect and Spanner JDBC Driver. The service accounts JSON credentials file location should be in the GOOGLE_APPLICATION_CREDENTIALS environment variable.
The benefits of using Hibernate ORM with Cloud Spanner include portability across databases and easier writing of create-read-update-delete (CRUD) logic. These benefits can increase developer productivity and speed up cloud database adoption.
In addition, there are many Hibernate-compatible frameworks such as Spring Boot, Microprofile, and Quarkus. Cloud Spanner Dialect for Hibernate ORM makes it possible to use Hibernate with Cloud Spanner. This can help migrate existing applications to the cloud or write new ones leveraging increased developer productivity afforded by Hibernate-based technologies.
Challenges with Hibernate
One challenge is getting the data retrieval just right. You can either fetch everything at once (eager fetching), which can be wasteful, or fetch data piece by piece (lazy fetching), which might lead to extra database calls later. There’s a sweet spot to find!
Another challenge is scaling things up. Hibernate’s built-in cache for speeding things up might cause issues in complex setups like microservices. There are better caching options for those situations. Bulk data updates can also be tricky with Hibernate and require careful configuration.
A fundamental challenge of Hibernate is that objects and databases don’t always see eye-to-eye. This can lead to complex queries and slowdowns.
There are also things to consider with how Hibernate handles updates from multiple users at the same time. It’s important to understand how this works to avoid data getting messed up.
Finally, while Hibernate is super convenient, it shouldn’t be the only tool in your shed. For complex tasks or to squeeze out the most performance, you might need to write some database queries directly.
By being aware of these challenges, you can use Hibernate effectively and avoid surprises in your applications.
How Can I Optimize Hibernate for Better Performance?
Hibernate is a powerful tool for object-relational mapping, but like any technology, it can benefit from some fine-tuning to achieve optimal performance. Here’s a deep dive into how you can squeeze the most out of your Hibernate configuration:
The first step is to identify where your application is hitting snags. There are two main ways to achieve this:
SQL Statement Logging: Enable Hibernate’s logging functionality to capture the exact SQL statements it generates. This allows you to analyze the queries and pinpoint any inefficient ones that might be causing slowdowns. By scrutinizing these statements, you can identify potential issues like complex joins or unnecessary data retrieval.
Profiling: Leverage a profiler to delve deeper into your application code’s performance characteristics. Profilers can pinpoint specific sections of code that are taking a long time to execute, helping you isolate areas where Hibernate interactions might be contributing to the bottleneck.
Once you’ve identified areas for improvement, it’s time to optimize your queries. Here are some key strategies:
Choosing the Right FetchType: Hibernate offers two primary options for fetching related entities: FetchType.LAZY and FetchType.EAGER. FetchType.LAZY is ideal for relationships that aren’t always needed immediately. It defers the loading of related entities until they are explicitly accessed in your code, reducing the number of database calls initially. Conversely, FetchType.EAGER fetches all related entities in a single query when the parent entity is loaded. This is suitable for situations where you always require both the parent and its related entities together, but overuse can lead to unnecessary data retrieval if not carefully considered.
JOIN FETCH for Eager Loading with a Single Query: JOIN FETCH is a powerful Hibernate feature that allows you to eagerly fetch related entities within the same query that retrieves the parent entity. This eliminates the need for separate N+1 queries (explained later) to load related data, significantly improving performance.
Combating N+1 Queries: N+1 queries occur when Hibernate fires off a separate query for each related entity after fetching a collection of parent entities. This can be quite inefficient. To avoid N+1 queries, you can employ techniques like batch fetching, which retrieves related entities in batches, or entity graphs, which allow you to specify the exact relationships you want to fetch along with the parent entity.
Caching plays a crucial role in optimizing performance. Hibernate offers two main caching layers:
Hibernate Caches: Hibernate maintains a first-level cache within each session, which stores recently accessed entities. This cache is local to the session and can significantly reduce database hits for frequently accessed data. Additionally, Hibernate supports a second-level cache, which can be configured to store entities across sessions, further enhancing performance for frequently used data.
Database Query Cache: Consider configuring your database to cache frequently executed queries. This allows the database to reuse the query plan instead of re-parsing it for each execution, leading to faster response times.
Beyond the strategies mentioned above, here are some other techniques to consider:
Database Indexing: Ensure that your database has proper indexes created on columns used in WHERE clauses and JOINs. Indexes act like shortcuts for the database, enabling it to quickly locate relevant data, leading to faster query execution.
Batch Updates and Deletes: Whenever possible, utilize batching for UPDATE and DELETE operations. This reduces the number of database roundtrips required, as Hibernate can send a single statement containing multiple updates or deletes, improving efficiency.
GenerationType Consideration: The GenerationType strategy you choose for your primary keys can impact batch updates. If you’re not using GenerationType.IDENTITY, you might be inadvertently disabling batch updates. GenerationType.IDENTITY lets the database generate IDs, which is generally recommended for optimal performance with batching.
Performance tuning is an ongoing process. It’s essential to continuously monitor your application’s performance and fine-tune your Hibernate configuration as needed. By using the strategies outlined above, you can ensure that your Hibernate implementation delivers optimal performance for your application.